Tutorial Selection HTML elements with BeautifulSoup
Posted in Uncategorized





For this tutorial, we install …
pip install beautifulsoup4
Then import “bs4” module and create instance of “BeautifulSoup” by passing into its constructor an HTML string and the parser to use…
The list of possible parser can be found in the docs here.
The first thing you see in the above example is that it can “prettify()” your HTML.
But that is not what we are here for. We want to select HTML elements (such as the paragraph tags) …

And it gives you back a list with all paragraph HTML like this…

If you use “find” instead of “find_all” it will only give you the first one found (and it won’t be in a list).
“find” will return None if nothing found. “find_all” will return empty list.
If you just want the first item found for a particular HTML tag like “p”, you can simply do …
soup.p
You can select by id like …
soup.find(id=”first_paragraph”)
You can also find by class…
soup.find_all(class_=”text_block”)
Note “class_” because “class” is a keyword in python.
You can find elements by tag attributes…
soup.find_all(attrs={“title”: “lorem ipsum”})
Select method
You can find by CSS selectors using the “select” method…
soup.select(“#first_paragraph”)
soup.select(“.text_block > strong”)
It always returns a list. A list of what? Not strings, but bs4.element.Tag objects.
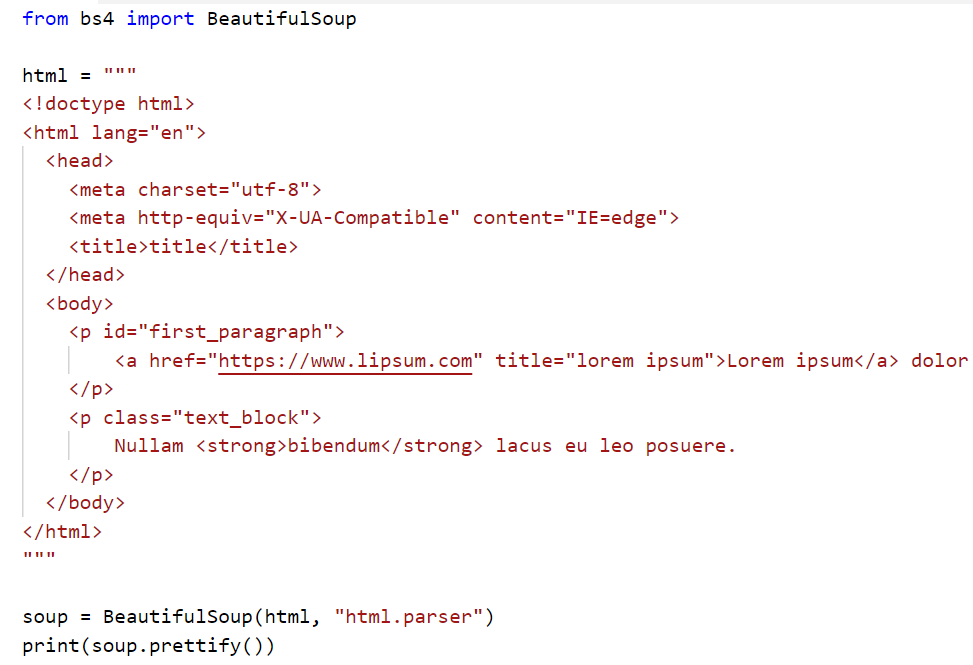
These objects has a method called get_text() which will give us the innerHTML text of the element. So …
The bs4.element.Tag object also has the “name” property (which is the name of the tag), and the “attrs” property (attributes of the tag), and the “contents ” property. For example…

Navigation
There are navigation properties to the Tag element such as …
parent / next_sibling / previous_sibling
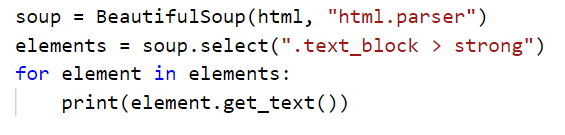
In the below example, after finding the first paragraph, we get its parent, which is the “body” element…
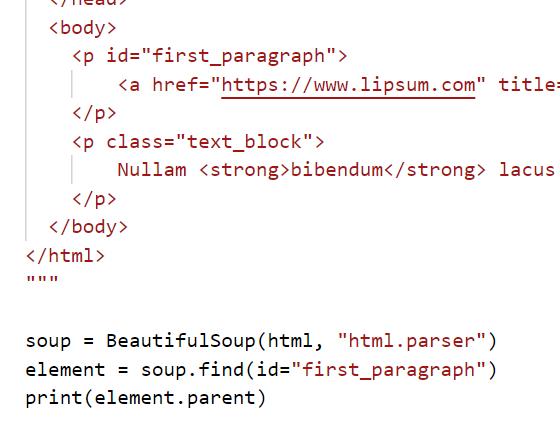
You would thing that next_sibling would get the next paragraph, but it got an “\n” newline element instead. We had to call next_sibling twice to get what we expected…

Alternatively, use “find_next_sibling” instead. It will find the next “element” and get what you expect…

There are the plural forms …
parents / next_siblings / previous_siblings
However these give you a generator. So you would do something like this to loop through …
Related Posts
Tags
Share This

